这篇文章主要总结了面试中需要掌握的几个方面,包括数据结构、算法和数据操作、高质量的代码、解决面试题的思路、优化时间和空间效率以及面试中的各项能力。在数据结构方面,需要掌握常见的数据结构,如数组、链表、栈、队列、树、图等,并能够熟练地进行操作。在算法和数据操作方面,需要掌握常见的算法,如排序、查找、递归、动态规划等,并能够熟练地运用到实际问题中。在高质量的代码方面,需要注意代码的可读性、可维护性和可扩展性,并且要遵循一定的编码规范。在解决面试题的思路方面,需要掌握常见的解题思路,如暴力枚举、贪心算法、分治算法等,并能够灵活运用到实际问题中。在优化时间和空间效率方面,需要注意算法的时间复杂度和空间复杂度,并能够对算法进行优化。在面试中的各项能力方面,需要注意沟通能力、团队合作能力、问题解决能力等。
剑指Offer总结
数据结构
数组
数组中重复的数字
思路:
利用一个辅助数组来表示数字是否已出现过了,如果已出现过则返回当前数字。
时间复杂度: \(O(n)\)
额外空间复杂度为 \(O(n)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public class DuplicateNumber { public static boolean duplicate (int [] arr, int [] duplication) { if (arr == null || arr.length < 2 ) return false ; boolean [] flag = new boolean [arr.length]; for (int e : arr){ if (flag[e]){ duplication[0 ] = e; return true ; } flag[e] = true ; } return false ; } public static void main (String[] args) { int [] arr = new int []{}, duplication = new int [1 ]; System.out.println(duplicate(arr, duplication)); System.out.println(duplication[0 ]); } }
二维数组中的查找
思路:
首先选取数组中右上角的数字。
如果该数字等于要查找的数字,则查找过程结束;
如果该数字大于要查找的数字,则剔除这个数字所在的列;
如果该数字小于要查找的数字,则剔除这个数字所在的行;
直到找到要查找的数字,或者查找范围为空。
时间复杂度: \(O(rows+cols)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 public class TwoDArrayFind { public boolean find (int [][] matrix, int target) { if (matrix == null || matrix.length == 0 ) return false ; int i = 0 , j = matrix[0 ].length - 1 ; while (i < matrix.length && j >= 0 ){ if (matrix[i][j] == target) return true ; if (matrix[i][j] < target) i++; else j--; } return false ; } }
字符串
替换空格
思路:
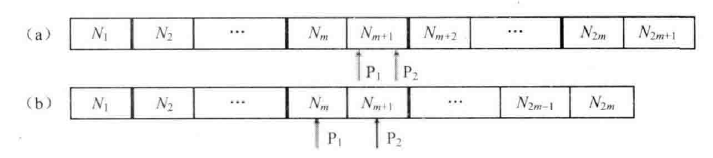
先遍历一次字符串,统计出字符串中空格的总数,并由此计算出替换后的字符串的总长度;每替换一个空格,长度就增长 2。
准备两个指针:\(P_1\) 和 \(P_2\) ,\(P_1\) 指向原始字符串的末尾,而 \(P_2\) 指向替换之后的字符串的末尾;
接着向前移动指针 \(P_1\) ,逐个把它指向的字符复制到 \(P_2\) 指向的位置,直到碰到空格为止;
碰到空格后,把 \(P_1\) 向前移动1格,在 \(P_2\) 之前插入字符串 "%20",由于 "%20" 的长度为 3,同时也要把 \(P_2\) 向前移动 3 格;
重复以上步骤,直至 \(P_1\) 和 \(P_2\) 指向同一位置。
时间复杂度: \(O(n)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution {public : void replaceSpace (char *str,int length) if (str == nullptr || length <= 0 ) return ; int originLen = 0 ; int numOfSpace = 0 ; int i = 0 ; while (str[i] != '\0' ){ ++originLen; if (str[i] == ' ' ) ++numOfSpace; ++i; } int indexOfOrigin = originLen; int indexOfNew = originLen + numOfSpace * 2 ; while (indexOfOrigin < indexOfNew){ if (str[indexOfOrigin] == ' ' ){ str[indexOfNew--] = '0' ; str[indexOfNew--] = '2' ; str[indexOfNew--] = '%' ; }else { str[indexOfNew--] = str[indexOfOrigin]; } indexOfOrigin--; } } };
把字符串转换成整数
思路:
把第一个字符分两种情况对待,第一种为符号位即 '+' 或 '-',第二种为 '0'-'9' 的数字字符。
从第一个数字字符开始到最后一个字符做如下运算:
每次循环将上一次的结果 * 10
然后加上本次循环的字符数字
时间复杂度: \(O(n)\)
参考实现:
未做溢出判断
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public class StrToInt { public static int strToInt (String str) { if (str == null || str.length() == 0 ) return 0 ; char signBit = str.charAt(0 ); if (signBit != '+' && signBit != '-' && (signBit < '0' || signBit > '9' )) return 0 ; int res = 0 , i = 1 ; if (signBit >= '0' ) i = 0 ; for (; i < str.length(); i++){ if (str.charAt(i) < '0' || str.charAt(i) > '9' ) return 0 ; res *= 10 ; res += (str.charAt(i) - '0' ); } return signBit == '-' ? -res : res; } public static void main (String[] args) { System.out.println(strToInt("+2147483647" )); System.out.println(strToInt("4562" )); System.out.println(strToInt("-87904562" )); } }
链表
从尾到头打印链表
思路:
直接从头到尾遍历链表,将遍历的结点都加入列表中,最后对列表进行逆序操作。
时间复杂度: \(O(n)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import java.util.ArrayList;import java.util.Collections;public class PrintListFromTailToHead { public ArrayList<Integer> printListFromTailToHead (ListNode pHead) { ArrayList<Integer> nodes = new ArrayList <>(); if (pHead == null ) return nodes; while (pHead != null ){ nodes.add(pHead.val); pHead = pHead.next; } Collections.reverse(nodes); return nodes; } }
树
重建二叉树
思路:
根据前序遍历的第一个数字创建根结点;
接着在中序遍历序列中找到根结点的位置,确定左、右子树的结点数量;
在前序遍历和中序遍历序列中划分了左、右子树结点的值后,递归地调用函数去分别构建它的左、右子树。
时间复杂度: \(O(n^2)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 public class ReconstructBinaryTree { public TreeNode constructCore (int [] pre, int [] in, int startPre, int endPre, int startIn, int endIn) { int rootValue = pre[startPre]; TreeNode root = new TreeNode (rootValue); if (startPre == endPre) return root; int rootIn = startIn; while (rootIn <= endIn && in[rootIn] != rootValue) rootIn++; int leftLen = rootIn - startIn; if (leftLen > 0 ){ root.left = constructCore(pre, in, startPre+1 , startPre+leftLen, startIn, rootIn-1 ); } if (leftLen < endPre - startPre){ root.right = constructCore(pre, in, startPre+leftLen+1 , endPre, rootIn+1 , endIn); } return root; } public TreeNode construct (int [] pre, int [] in) { if (pre == null || in == null || pre.length == 0 || pre.length != in.length) return null ; return constructCore(pre, in, 0 , pre.length-1 , 0 , in.length-1 ); } }
二叉树的下一个结点
思路:
如果一个结点有右子树,那么它的下一个结点就是它右子树中的最左结点。
如果一个结点没有右子树,则分两种情况:
如果结点是它父结点的左子结点,那么它的下一个结点即为它的父结点。
如果结点是它父结点的右子结点,则可以沿着父结点的指针一直向上遍历,直到找到一个是它父结点的左子结点,如果这样的结点存在,那么这个结点的父结点就是要找的下一个结点。
时间复杂度: \(O(logn)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class TreeLinkNode { int val; TreeLinkNode left = null ; TreeLinkNode right = null ; TreeLinkNode next = null ; TreeLinkNode(int val) { this .val = val; } } public class GetNext { public TreeLinkNode getNext (TreeLinkNode pNode) { if (pNode == null ) return null ; TreeLinkNode pNext; if (pNode.right != null ){ TreeLinkNode pRight = pNode.right; while (pRight.left != null ) pRight = pRight.left; pNext = pRight; }else { TreeLinkNode pCurrent = pNode, pParent = pNode.next; while (pParent != null && pCurrent == pParent.right){ pCurrent = pParent; pParent = pCurrent.next; } pNext = pParent; } return pNext; } }
栈和队列
用两个栈实现队列
思路:
入队时,直接将元素压入 stack1
出队时分两种情况:
若 stack2 不空,则弹出 stack2 栈顶;
若 stack2 为空,则将 stack1 中的元素逐个弹出并压入 stack2,然后再弹出 stack2 栈顶。
时间复杂度: 入队 \(O(1)\) ,出队 \(O(1) \sim O(n)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import java.util.Stack;public class TwoStacksToQueue { Stack<Integer> stack1 = new Stack <>(); Stack<Integer> stack2 = new Stack <>(); public void push (int node) { stack1.push(node); } public int pop () { if (stack2.isEmpty()) { while (!stack1.isEmpty()) stack2.push(stack1.pop()); } return stack2.pop(); } }
算法和数据操作
递归和循环
斐波那契数列
思路:
从下往上计算,首先根据 \(f(0)\) 和 \(f(1)\) 算出 \(f(2)\) ,再根据 \(f(1)\) 和 \(f(2)\) 算出 \(f(3)\) ... 以此类推就可以算出第 n 项了。
时间复杂度: \(O(n)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class Fibonacci { public int fibonacci (int n) { int f1 = 0 , f2 = 1 ; if (n == 0 ) return f1; if (n == 1 ) return f2; for (int i = 2 ; i <= n; i++){ int tmp = f1 + f2; f1 = f2; f2 = tmp; } return f2; } }
青蛙跳台阶
思路:
把 \(n\) 级台阶时的跳法看成 \(n\) 的函数,记为 \(f(n)\) :
显然有 \(f(1)=1,f(2)=2\)
当 \(n \gt 2\) 时,\(f(n)=f(n-1)+f(n-2)\)
时间复杂度: \(O(n)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class FrogJumpSteps { public int jumpFloor (int n) { int f1 = 1 , f2 = 2 ; if (n == 1 ) return f1; if (n == 2 ) return f2; for (int i = 3 ; i <= n; i++){ int tmp = f1 + f2; f1 = f2; f2 = tmp; } return f2; } }
变态跳台阶
思路:
\(f(n)=2^{n-1}\)
时间复杂度: \(O(n)\)
参考实现:
1 2 3 4 5 public class FrogJumpStepsII { public int jumpFloorII (int n) { return (int ) Math.pow(2 , n - 1 ); } }
矩阵覆盖
思路:
\(f(1)=1,f(2)=2\)
当 \(n > 2\) 时,\(f(n)=f(n-1)+f(n-2)\)
时间复杂度: \(O(n)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 public class RectCover { public int rectCover (int n) { int [] f = new int []{0 , 1 , 2 }; if (n < 3 ) return f[n]; for (int i = 3 ; i <= n; i++){ f[0 ] = f[1 ] + f[2 ]; f[1 ] = f[2 ]; f[2 ] = f[0 ]; } return f[2 ]; } }
查找和排序
旋转数组的最小数字
思路:
定义两个指针 \(P_1\) 和 \(P_2\) ,\(P_1\) 总是指向前面递增的数组的元素,而 \(P_2\) 总是指向后面递增数组的元素。
初始时,\(P_1\) 指向数组的第一个元素,\(P_2\) 指向数组的最后一个元素。
如果 \(arr[P_1] \le arr[P_2]\) ,则直接进行顺序查找;
如果 \(arr[P_1] \gt arr[P_2]\) ,则进行如下步骤:
找到 \(P_1\) 和 \(P_2\) 的中间元素,如果该中间元素位于前面的递增子数组,则把 \(P_1\) 指向该中间元素;
如果该中间元素位于后面的递增子数组,则把 \(P_2\) 指向该中间元素;
重复以上步骤,直至两个指针相邻时,\(P_2\) 指向的元素即为最小的元素。
时间复杂度: \(O(logn)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public class MinNumberInRotateArray { public int minNumberInRotateArray (int [] arr) { if (arr == null || arr.length == 0 ) return 0 ; int p1 = 0 , p2 = arr.length - 1 ; if (p1 == p2 || arr[p1] < arr[p2]) return p1; if (arr[p1] == arr[p2]){ for (int i = 1 ; i < arr.length; i++) if (arr[i] < arr[p1]) p1 = i; return arr[p1]; } while (p2 - p1 != 1 ){ int mid = (p1 + p2) / 2 ; if (arr[mid] >= arr[p1]) p1 = mid; else p2 = mid; } return arr[p2]; } }
回溯法
矩阵中的路径
思路:
利用回溯法:
首先在矩阵中任选一个格子作为路径的起点。假设矩阵中某个格子的字符为 ch,并且这个格子将对应于路径上的第 i 个字符。
如果路径上的第 i 个字符不是 ch,那么这个格子不可能处在路径上的第 i 个位置。
如果路径上的第 i 个字符正好是 ch,那么就到相邻的格子寻找路径上的第 i+1 个字符。
除矩阵边界上的格子之外,其它格子都有 4 个相邻的格子。
重复这个过程,直到路径上的所有字符都在矩阵中找到相应的位置。
时间复杂度: \(O(rows \ast cols \ast str.length)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 public class MatrixPath { private boolean hasPathCore (char [] matrix, int rows, int cols, int i, int j, char [] str, int [] pathLen, boolean [] visited) { if (pathLen[0 ] == str.length) return true ; boolean hasPath = false ; if (i >= 0 && i < rows && j >= 0 && j < cols && matrix[i*cols+j] == str[pathLen[0 ]] && !visited[i*cols+j]){ pathLen[0 ]++; visited[i*cols+j] = true ; hasPath = hasPathCore(matrix, rows, cols, i, j-1 , str, pathLen, visited) || hasPathCore(matrix, rows, cols, i-1 , j, str, pathLen, visited) || hasPathCore(matrix, rows, cols, i, j+1 , str, pathLen, visited) || hasPathCore(matrix, rows, cols, i+1 , j, str, pathLen, visited); if (!hasPath){ pathLen[0 ]--; visited[i*cols+j] = false ; } } return hasPath; } public boolean hasPath (char [] matrix, int rows, int cols, char [] str) { if (matrix == null || rows < 1 || cols < 1 || str == null ) return false ; boolean [] visited = new boolean [rows * cols]; int [] pathLen = new int [1 ]; for (int i = 0 ; i < rows; i++){ for (int j = 0 ; j < cols; j++){ if (hasPathCore(matrix, rows, cols, i, j, str, pathLen, visited)) return true ; } } return false ; } }
机器人的运动范围
思路:
利用回溯法:
机器人从坐标 (0,0) 开始移动。
当它准备进入坐标为 (i,j) 的格子时,通过检查坐标的数位和来判断机器人是否能够进入。
如果机器人能够进入坐标为 (i,j) 的格子,则计数加 1;然后再判断它能否进入右方和下方的格子 (i,j+1),(i+1,j)。
时间复杂度: \(O(rows*cols)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 public class RobotMoveArea { private int getDigitSum (int num) { int sum = 0 ; while (num != 0 ){ sum += num % 10 ; num /= 10 ; } return sum; } private boolean check (int threshold, int rows, int cols, int i, int j, boolean [] visited) { return i >= 0 && i < rows && j >= 0 && j < cols && getDigitSum(i) + getDigitSum(j) <= threshold && !visited[i * cols + j]; } private int movingCountCore (int threshold, int rows, int cols, int i, int j, boolean [] visited) { int count = 0 ; if (check(threshold, rows, cols, i, j, visited)) { visited[i*cols+j] = true ; count = 1 + movingCountCore(threshold, rows, cols, i, j+1 , visited) + movingCountCore(threshold, rows, cols, i+1 , j, visited); } return count; } public int movingCount (int threshold, int rows, int cols) { if (threshold < 0 || rows <= 0 || cols <= 0 ) return 0 ; boolean [] visited = new boolean [rows * cols]; return movingCountCore(threshold, rows, cols, 0 , 0 , visited); } }
动态规划与贪心算法
位运算
二进制中1的个数
思路:
把一个整数减去 1,再和原整数做与运算,会把该整数最右边的 1 变成 0。
时间复杂度: \(O(1)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 public class NumberOf1 { public int numberOf1 (int n) { int count = 0 ; while (n != 0 ){ count++; n &= (n-1 ); } return count; } }
高质量的代码
代码的完整性
数值的整数次方
思路:
快速幂
时间复杂度: \(O(1)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class PowerWithIntExponent { public double power (double base, int exp) { double res = 1 ; boolean isNegative = false ; if (exp < 0 ){ isNegative = true ; exp = -exp; if (base == 0.0 ) return 0.0 ; } while (exp != 0 ){ if ((exp & 1 ) == 1 ) res *= base; exp >>= 1 ; base *= base; } return isNegative ? 1.0 / res : res; } }
打印1到最大的n位数
思路:
如果我们在数字前面补 0,就会发现 n 位所有十进制其实就是 n 个从 0 到 9 的全排列。即如果把数字的每一位都从 0 到 9 排列一遍,就得到了所有的十进制数。只是在打印的时候,排在前面的 0 不打印出来罢了。
时间复杂度: \(O(10^n)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 public class PrintToMaxOfNDigits { private void printNumber (char [] num) { boolean isZero = true ; for (int i = 0 ; i < num.length; i++){ if (isZero && num[i] != '0' ) isZero = false ; if (!isZero) System.out.print(num[i]); } if (isZero) System.out.println("0" ); else System.out.println(); } private void printRecursively (char [] num, int index) { if (index == num.length - 1 ){ printNumber(num); return ; } for (int i = 0 ; i < 10 ; i++){ num[index + 1 ] = (char ) (i + '0' ); printRecursively(num, index + 1 ); } } public void PrintToMaxOfNDigits (int n) { if (n <= 0 ) return ; char [] num = new char [n]; for (int i = 0 ; i < 10 ; i++){ num[0 ] = (char ) (i + '0' ); printRecursively(num, 0 ); } } public static void main (String[] args) { new PrintToMaxOfNDigits ().PrintToMaxOfNDigits(2 ); } }
在O(1)时间删除链表结点
思路:
对于 n-1 个非尾结点,可以在 \(O(1)\) 时间内把下一个结点的内容复制覆盖要删除的结点,并删除下一个结点;对于尾结点,仍需要顺序查找,然后进行删除,时间复杂度是 \(O(n)\) ;总的平均时间复杂度为 \([(n-1)*O(1)+O(n)]/n\) ,结果为 \(O(1)\)
时间复杂度: \(O(1)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import Offer.ListNode;public class DeleteNode { public void delete (ListNode[] pHead, ListNode[] pDel) { if (pHead == null || pDel == null ) return ; if (pDel[0 ].next != null ){ ListNode pNode = pDel[0 ].next; pDel[0 ].val = pNode.val; pDel[0 ].next = pNode.next; pNode.next = null ; }else if (pDel == pHead){ pDel[0 ] = null ; pHead[0 ] = null ; }else { ListNode pNode = pHead[0 ]; while (pNode.next != pDel[0 ]) pNode = pNode.next; pNode.next = null ; pDel[0 ] = null ; } } }
删除链表中重复的结点
思路:
遍历整个链表:
如果当前结点的值与下一个结点的值相同,那么它们都要被删除。
为保证删除后的链表仍是相连的,要把当前结点的前一个结点和后面值比当前结点值大的结点相连。
确保前一个结点始终与下一个没有重复的结点连接在一起。
时间复杂度: \(O(n)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 public class DeleteDuplication { public ListNode deleteDuplication (ListNode pHead) { ListNode first = new ListNode (-1 ); first.next = pHead; ListNode pNode = pHead; ListNode last = first; while (pNode != null && pNode.next != null ){ if (pNode.val == pNode.next.val){ int val = pNode.val; while (pNode != null && pNode.val == val) pNode = pNode.next; last.next = pNode; }else { last = pNode; pNode = pNode.next; } } return first.next; } public static void main (String[] args) { int [] arr = new int []{1 ,2 ,3 ,3 ,4 ,4 ,5 }; ListNode pHead = new ListNode (arr[0 ]); ListNode pNode = pHead; for (int i = 1 ; i < arr.length; i++){ ListNode tmp = new ListNode (arr[i]); pNode.next = tmp; pNode = tmp; } ListNode res = new DeleteDuplication ().deleteDuplication(pHead); while (res != null ){ System.out.println(res.val); res = res.next; } } }
正则表达式匹配
思路:
根据模式中第二个字符是否为 * 分两种情况考虑:
模式中的第二个字符不是 * 时
如果字符串中的第一个字符和模式的第一个字符相匹配,则字符串和模式都向后移动一个字符,然后继续匹配剩余字符。
如果字符串中的第一个字符和模式的第一个字符不匹配,则直接返回 false
模式中的第二个字符是 * 时,有多种匹配模式
如果字符串第一个字符和模式第一个字符 不匹配 ,则模式后移两个字符,然后继续匹配剩余字符
如果字符串第一个字符和模式第一个字符 匹配 ,可以有 3 种匹配方式:
字符串后移 1 个字符,模式不变
模式后移 2 个字符,相当于 x* 被忽略
字符串后移 1 个字符,模式后移 2 个字符
时间复杂度: \(O(n)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 public class RegularMatch { public static boolean match (char [] str, char [] pattern) { if (str == null || pattern == null ) return false ; return matchCore(str, 0 , pattern, 0 ); } private static boolean matchCore (char [] str, int idxStr, char [] pattern, int idxPat) { if (idxStr == str.length && idxPat == pattern.length) return true ; if (idxStr != str.length && idxPat == pattern.length) return false ; if (idxPat + 1 < pattern.length && pattern[idxPat + 1 ] == '*' ){ if (idxStr != str.length && (pattern[idxPat] == str[idxStr] || pattern[idxPat] == '.' )) return matchCore(str, idxStr + 1 , pattern, idxPat + 2 ) || matchCore(str, idxStr + 1 , pattern, idxPat) || matchCore(str, idxStr, pattern, idxPat + 2 ); else return matchCore(str, idxStr, pattern, idxPat + 2 ); } if (idxStr != str.length && (str[idxStr] == pattern[idxPat] || pattern[idxPat] == '.' )) return matchCore(str, idxStr + 1 , pattern, idxPat + 1 ); return false ; } public static void main (String[] args) { System.out.println(match("aaa" .toCharArray(), "ab*ac*a" .toCharArray())); System.out.println(match("" .toCharArray(), ".*" .toCharArray())); } }
表示数值的字符串
思路:
表示数值的字符串遵循模式 A[.[B]][e|EC] 或者 .B[e|EC],其中:
A 为数值的整数部分(可能以 '+' 或 '-' 开头的 0-9 的数位串)
B 紧跟着小数点为数值的小数部分(0-9 的数位串)
C 紧跟 'e' 或 'E' 为数值的指数部分(可能以 '+' 或 '-' 开头的 0-9 的数位串)
在小数里可能没有整数部分,如小数 .123 等于 0.123,因此 A 部分不是必需的。如果一个数没有整数部分,那么它的小数部分不能为空。
时间复杂度: \(O(n)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 public class IsNumeric { private static boolean scanUnsignedInteger (char [] str, int [] idx) { int startIdx = idx[0 ]; while (idx[0 ] < str.length && str[idx[0 ]] >= '0' && str[idx[0 ]] <= '9' ) idx[0 ]++; return idx[0 ] > startIdx; } private static boolean scanInteger (char [] str, int [] idx) { if (idx[0 ] < str.length && (str[idx[0 ]] == '+' || str[idx[0 ]] == '-' )) idx[0 ]++; return scanUnsignedInteger(str, idx); } public static boolean isNumeric (char [] str) { if (str == null || str.length == 0 ) return false ; int [] idx = new int []{0 }; boolean numeric = scanInteger(str, idx); if (idx[0 ] != str.length && str[idx[0 ]] == '.' ){ idx[0 ]++; numeric = scanUnsignedInteger(str, idx) || numeric; } if (idx[0 ] != str.length && (str[idx[0 ]] == 'e' || str[idx[0 ]] == 'E' )){ idx[0 ]++; numeric = numeric && scanInteger(str, idx); } return numeric && idx[0 ] == str.length; } public static void main (String[] args) { System.out.println(isNumeric(".123" .toCharArray())); System.out.println(isNumeric("123." .toCharArray())); System.out.println(isNumeric(".e2" .toCharArray())); System.out.println(isNumeric("12e" .toCharArray())); } }
调整数组顺序使奇数位于偶数前面
思路:
定义两个指针 \(P_1\) 和 \(P_2\) ,\(P_1\) 指向数组的第一个数字,\(P_2\) 指向最后一个数字;
\(P_1\) 向后移动直至它指向偶数;\(P_2\) 向前移动直至它指向奇数;交换 \(P_1\) 和 \(P_2\) 指向的元素;
直到 \(P_1\) 和 \(P_2\) 相遇。
时间复杂度: \(O(n)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class ReorderOddEven { private void swap (int [] arr, int i, int j) { int tmp = arr[i]; arr[i] = arr[j]; arr[j] = tmp; } public void reorderOddEven (int [] arr) { if (arr == null || arr.length < 2 ) return ; int p1 = 0 , p2 = arr.length - 1 ; while (p1 < p2){ while (p1 < p2 && (arr[p1] & 1 ) == 1 ) p1++; while (p1 < p2 && (arr[p2] & 1 ) == 0 ) p2--; if (p1 < p2) swap(arr, p1, p2); } } }
调整数组顺序使奇数位于偶数前面(扩展)
调整后保证奇数和奇数,偶数和偶数之间的相对位置不变。
思路:
空间换时间
遍历两次数组,第一次遍历时将全部的奇数按顺序保存到辅助数组;
第二次遍历时将全部的偶数按顺序追加到数组尾部。
时间复杂度: \(O(n)\)
额外空间复杂度为 \(O(n)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 public class ReorderOddEvenII { public void reOrderArray (int [] arr) { if (arr == null || arr.length < 2 ) return ; int [] res = new int [arr.length]; int k = 0 ; for (int e : arr) if ((e & 1 ) == 1 ) res[k++] = e; for (int e : arr) if ((e & 1 ) == 0 ) res[k++] = e; System.arraycopy(res, 0 , arr, 0 , k); } }
代码的鲁棒性
链表中倒数第 k 个结点
思路:
假设整个链表有 n 个结点,那么倒数第 k 个结点就是从头结点开始的第 n-k+1 个结点。
遍历一次链表,得到链表长度 n;
第二次遍历时,从头结点开始指针前进 n-k+1 步,即为倒数第 k 个结点。
上面的方法需要遍历两次链表,但我们有只需要遍历一次链表的解法。
定义两个指针,第一个指针从链表的头指针开始遍历向前走 k-1 步,第二个指针保持不动;
从第 k 步开始,第二个指针也开始从链表的的头指针开始遍历;
由于两个指针的距离保持在 k-1,当第一个(走在前面的)指针到达链表的尾结点时,第二个(走在后面的)指针正好指向倒数第 k 个结点。
时间复杂度: \(O(n)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class FindKthToTail { public ListNode findKthToTail (ListNode pHead, int k) { if (pHead == null || k < 1 ) return null ; ListNode p1 = pHead, p2 = pHead; for (int i = 0 ; i < k - 1 && p1 != null ; i++) p1 = p1.next; if (p1 == null ) return null ; while (p1.next != null ){ p1 = p1.next; p2 = p2.next; } return p2; } }
链表中环的入口结点
思路:
第一步确定一个链表中是否包含环
定义两个指针,同时从链表头结点出发,一个指针一次走一步,另一个指针一次走两步;
如果走得快的指针追上了走得慢的指针,那么链表就包含环;
如果走得快的指针到了链表末尾也没有追上第一个指针,那么链表就不包含环。
第二步统计环中的结点数
两个指针相遇的结点一定是在环中的,可以从这个结点出发;
一边继续向前移动一边计数,当再次回到这个结点时,就可以得到环中结点数了。
第三步找到环的入口
定义两个指针 \(P_1\) 和 \(P_2\) 指向链表头结点,如果链表中的环有 n 个结点,则指针 \(P_1\) 先在链表上向前移动 n 步;
然后两个指针以相同的速度向前移动;
当两个指针相遇时,指针指向的结点即为环的入口结点。
时间复杂度: \(O(n)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 class ListNode { int val; ListNode next = null ; ListNode(int val) { this .val = val; } } public class EntryNodeOfLoop { private ListNode meetingNode (ListNode pHead) { ListNode pSlow = pHead, pFast = pHead.next; while (pFast != null ){ if (pFast == pSlow) return pFast; pSlow = pSlow.next; pFast = pFast.next; if (pFast != null ) pFast = pFast.next; } return null ; } public ListNode entryNodeOfLoop (ListNode pHead) { if (pHead == null || pHead.next == null ) return null ; ListNode meetNode = meetingNode(pHead); if (meetNode == null ) return null ; int nodesInLoop = 1 ; ListNode pNode = meetNode; while (pNode.next != meetNode){ pNode = pNode.next; nodesInLoop++; } ListNode pNode1 = pHead, pNode2 = pHead; for (int i = 0 ; i < nodesInLoop; i++) pNode1 = pNode1.next; while (pNode1 != pNode2){ pNode1 = pNode1.next; pNode2 = pNode2.next; } return pNode1; } public static void main (String[] args) { EntryNodeOfLoop entryNodeOfLoop = new EntryNodeOfLoop (); ListNode node6 = new ListNode (6 ); ListNode node5 = new ListNode (5 ); ListNode node4 = new ListNode (4 ); ListNode node3 = new ListNode (3 ); ListNode node2 = new ListNode (2 ); ListNode node1 = new ListNode (1 ); node1.next = node2; node2.next = node3; node3.next = node4; node4.next = node5; node5.next = node6; node6.next = node3; ListNode entryNode = entryNodeOfLoop.entryNodeOfLoop(node1); System.out.println(entryNode.val); } }
反转链表
思路:
定义 3 个指针,分别指向当前遍历到的结点、它的前一个结点及后一个结点。
时间复杂度: \(O(n)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class ReverseList { public ListNode reverseList (ListNode pHead) { if (pHead == null ) return null ; ListNode pPrev = null ; ListNode pNode = pHead; ListNode pNext; while (pNode != null ){ pNext = pNode.next; pNode.next = pPrev; pPrev = pNode; pNode = pNext; } return pPrev; } }
合并两个排序的链表
思路:
把两个链表中值较小的头结点链接到已合并的链表之后,两个链表剩余的结点依然是排序的,因此合并的步骤和之前的步骤是一样的。
时间复杂度: \(O(n)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 public class MergeTwoOrderedList { public ListNode merge (ListNode pHead1, ListNode pHead2) { if (pHead1 == null ) return pHead2; if (pHead2 == null ) return pHead1; ListNode pResHead; if (pHead1.val < pHead2.val){ pResHead = pHead1; pResHead.next = merge(pHead1.next, pHead2); }else { pResHead = pHead2; pResHead.next = merge(pHead1, pHead2.next); } return pResHead; } public ListNode mergeII (ListNode pHead1, ListNode pHead2) { if (pHead1 == null ) return pHead2; if (pHead2 == null ) return pHead1; ListNode pResHead, pResEnd, pNode1, pNode2; if (pHead1.val < pHead2.val){ pResHead = pResEnd = pHead1; pNode1 = pHead1.next; pNode2 = pHead2; }else { pResHead = pResEnd = pHead2; pNode1 = pHead1; pNode2 = pHead2.next; } while (pNode1 != null && pNode2 != null ){ ListNode minNode; if (pNode1.val < pNode2.val){ minNode = pNode1; pNode1 = pNode1.next; }else { minNode = pNode2; pNode2 = pNode2.next; } pResEnd = pResEnd.next = minNode; } pResEnd.next = (pNode1 != null ) ? pNode1 : pNode2; return pResHead; } }
树的子结构
思路:
分两步:第一步,在树 A 中找到和树 B 的根结点的值一样的结点 R;第二步,判断树 A 中以 R 为根结点的子树是否包含和树 B 一样的结构。
对于第二步同样可以用递归的思路来考虑:如果结点 R 的值和树 B 的根结点不同,则以 R 为根结点的子树和树 B 肯定不具有相同的结点;如果它们的值相同,则递归地判断它们各自的左右结点的值是不是相同。递归终止的条件是我们达到了树 A 或者树 B 的叶子结点。
时间复杂度: \(O(n*m)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public class HasSubTree { private boolean doesTree1HaveTree2 (TreeNode pRoot1, TreeNode pRoot2) { if (pRoot2 == null ) return true ; if (pRoot1 == null ) return false ; if (pRoot1.val == pRoot2.val) return doesTree1HaveTree2(pRoot1.left, pRoot2.left) && doesTree1HaveTree2(pRoot1.right, pRoot2.right); return false ; } public boolean hasSubTree (TreeNode pRoot1, TreeNode pRoot2) { boolean result = false ; if (pRoot1 != null && pRoot2 != null ){ if (pRoot1.val == pRoot2.val) result = doesTree1HaveTree2(pRoot1, pRoot2); if (!result) result = hasSubTree(pRoot1.left, pRoot2); if (!result) result = hasSubTree(pRoot1.right, pRoot2); } return result; } }
解决面试题的思路
面试官谈面试思路
二叉树的镜像
思路:
前序遍历树的每一个结点,如果遍历到的结点有子结点,就交换它的两个子结点。当交换完所有非叶子结点的左、右子结点之后,就得到了树的镜像。
时间复杂度: \(O(n)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 public class BinaryTreeMirror { public void mirror (TreeNode pRoot) { if (pRoot == null ) return ; TreeNode left = pRoot.left; TreeNode right = pRoot.right; pRoot.left = right; pRoot.right = left; if (left != null ) mirror(left); if (right != null ) mirror(right); } }
对称的二叉树
思路:
定义一种对称的前序遍历算法,即先遍历父结点,再遍历它的右子结点,最后遍历它的左子结点。
针对一颗二叉树,分别使用前序遍历算法和对称的前序遍历算法进行遍历,如果两次遍历得到的序列一样,则该二叉树是对称的。
注:遍历的过程中需要把 null 结点也考虑在内。
时间复杂度: \(O(n)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class TreeNode { int val; TreeNode left = null ; TreeNode right = null ; TreeNode(int val) { this .val = val; } } public class IsSymmetrical { private boolean isSymmetrical (TreeNode pRoot1, TreeNode pRoot2) { if (pRoot1 == null && pRoot2 == null ) return true ; if (pRoot1 == null || pRoot2 == null ) return false ; if (pRoot1.val != pRoot2.val) return false ; return isSymmetrical(pRoot1.left, pRoot2.right) && isSymmetrical(pRoot1.right, pRoot2.left); } public boolean isSymmetrical (TreeNode pRoot) { return isSymmetrical(pRoot, pRoot); } }
画图让抽象问题形象化
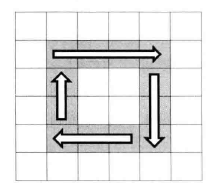
顺时针打印矩阵
思路:
由于是以外圈到内圈的顺序依次打印的,所以我们可以把矩阵想象成若干个圈,如下图所示,可以用一个循环来打印矩阵,每次打印矩阵中的一个圈。
假设矩阵的行数为 rows,列数为 cols,则循环结束的条件为: cols > startX * 2 && rows > startY * 2, (startX, startY) 为本次循环要打印的第一个位置的坐标。
接着我们考虑如何打印一圈的功能,即如何实现 printMatrixInCircle。我们可以把打印一圈分成四步:
第一步,从左到右打印一行;
第二步,从上到下打印一列;
第三步,从右到左打印一行;
第四步,从下到上打印一列。
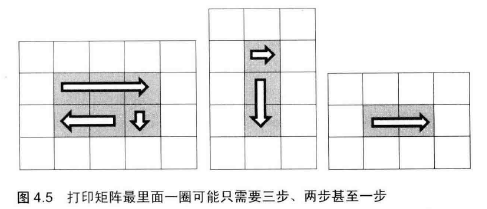
几个退化的例子:
经分析发现,第一步总是需要的;
如果只有一行,那就不用第二步了,也即进行第二步的前提条件是终止行号大于起始行号;
需要第三步的前提条件是圈内至少有两行两列,也就是说除了要求终止行号大于起始行号,还有终止列号大于起始列号。
同理,第四步的前提条件是至少有三行两列,因此要求终止行号比起始行号至少大 2,同时终止列号大于起始列号。
时间复杂度: \(O(n*m)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import java.util.ArrayList;public class PrintMatrixClockwisely { private void printMatrixInCircle (int [][] matrix, int rows, int cols, int start, ArrayList<Integer> res) { int endX = cols - 1 - start, endY = rows - 1 - start; for (int i = start; i <= endX; i++) res.add(matrix[start][i]); if (endY > start) for (int i = start + 1 ; i <= endY; i++) res.add(matrix[i][endX]); if (endY > start && endX > start) for (int i = endX - 1 ; i >= start; i--) res.add(matrix[endY][i]); if (endX > start && endY - start > 1 ) for (int i = endY - 1 ; i > start; i--) res.add(matrix[i][start]); } public ArrayList<Integer> printMatrixClockwisely (int [][] matrix) { ArrayList<Integer> res = new ArrayList <>(); if (matrix == null || matrix.length == 0 ) return res; int rows = matrix.length, cols = matrix[0 ].length, start = 0 ; while (cols > start * 2 && rows > start * 2 ) printMatrixInCircle(matrix, rows, cols, start++, res); return res; } }
举例让抽象问题具体化
包含 min 函数的栈
思路:
使用两个栈,数据栈和辅助栈;
每当数据栈压入数据后,辅助栈压入当前数据栈的最小值;
每当数据栈弹出数据后,辅助栈也直接弹出栈顶元素。
时间复杂度: min 函数 \(O(1)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import java.util.LinkedList;public class StackWithMin { private LinkedList<Integer> dataStack = new LinkedList <>(); private LinkedList<Integer> minStack = new LinkedList <>(); public void push (int num) { dataStack.push(num); if (minStack.isEmpty()) minStack.push(num); else { int curMin = minStack.peek(); minStack.push((num < curMin) ? num : curMin); } } public void pop () { dataStack.pop(); minStack.pop(); } public int top () { return dataStack.peek(); } public int min () { return minStack.peek(); } }
栈的压入、弹出序列
思路:
建立一个辅助栈,把输入的第一个序列中的数字依次压入该辅助栈,并按照第二个序列的顺序依次从该栈中弹出数字。
判断一个序列是不是栈的弹出序列的规律:
如果下一个弹出的数字刚好是栈顶数字,那么直接弹出;
如果下一个弹出的数字不在栈顶,则把压栈序列中还没有入栈的数字压入辅助栈,直到把下一个需要弹出的数字压入栈顶为止;
如果所有数字都压入栈后仍然没有找到下一个弹出的数字,那么该序列不可能是一个弹出序列。
时间复杂度: \(O(n)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import java.util.LinkedList;public class IsPopOrder { public boolean isPopOrder (int [] pPush, int [] pPop) { if (pPush == null || pPop == null || pPush.length != pPop.length || pPush.length == 0 ) return false ; int curPush = 0 , curPop = 0 ; LinkedList<Integer> stack = new LinkedList <>(); while (curPop < pPop.length){ while (stack.isEmpty() || stack.peek() != pPop[curPop]){ if (curPush == pPush.length) break ; stack.push(pPush[curPush++]); } if (stack.peek() != pPop[curPop]) break ; stack.pop(); curPop++; } return curPop == pPop.length; } }
从上到下打印二叉树
思路:
使用一个辅助队列,每次打印一个结点的时候,如果该结点有子结点,则把该结点的子结点放入队列的尾部。接着取出队列的下一个结点,重复前面的打印操作。
时间复杂度: \(O(n)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import java.util.ArrayList;import java.util.LinkedList;public class PrintFromTopToBottom { public ArrayList<Integer> printFromTopToBottom (TreeNode root) { ArrayList<Integer> res = new ArrayList <>(); if (root == null ) return res; LinkedList<TreeNode> queue = new LinkedList <>(); queue.offer(root); while (!queue.isEmpty()){ TreeNode node = queue.poll(); res.add(node.val); if (node.left != null ) queue.offer(node.left); if (node.right != null ) queue.offer(node.right); } return res; } }
分行从上到下打印二叉树
思路:
使用一个辅助队列来保存将要打印的结点;其次需要定义两个变量:一个变量 last 表示当前层的尾结点;另一个变量 nextLast 表示下一层的尾结点。
在打印某一层结点时,把下一层的子结点保存到队列中。
在把下一层的结点加到队列时,同步更新 nextLast,使 nextLast 指向队列的尾结点。
在打印到本层的尾结点时,更新 last,使 last = nextLast
时间复杂度: \(O(n)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import java.util.ArrayList;import java.util.LinkedList;public class LayerPrintTree { public ArrayList<ArrayList<Integer>> print (TreeNode pRoot) { ArrayList<ArrayList<Integer>> layerList = new ArrayList <>(); if (pRoot == null ) return layerList; LinkedList<TreeNode> queue = new LinkedList <>(); queue.offer(pRoot); TreeNode last = pRoot, nextLast = pRoot; ArrayList<Integer> layer = new ArrayList <>(); while (!queue.isEmpty()){ TreeNode pNode = queue.poll(); layer.add(pNode.val); if (pNode.left != null ){ queue.offer(pNode.left); nextLast = pNode.left; } if (pNode.right != null ){ queue.offer(pNode.right); nextLast = pNode.right; } if (pNode == last){ last = nextLast; layerList.add(layer); layer = new ArrayList <>(); } } return layerList; } }
之字形打印二叉树
思路:
使用两个辅助栈:
在打印某一层结点时,把下一层的子结点保存到相应的栈里。
如果当前打印的奇数层(第 1 层、第 3 层等),则先保存左子结点再保存右子结点到第一个栈里;
如果当前打印的是偶数层(第 2 层、第 4 层等),则先保存右子结点再保存左子结点到第二个栈里。
时间复杂度: \(O(n)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 import java.util.ArrayList;import java.util.Arrays;import java.util.LinkedList;public class ZPrintTree { public ArrayList<ArrayList<Integer>> print (TreeNode pRoot) { ArrayList<ArrayList<Integer>> layerList = new ArrayList <>(); if (pRoot == null ) return layerList; LinkedList[] levels = new LinkedList [2 ]; levels[0 ] = new LinkedList <TreeNode>(); levels[1 ] = new LinkedList <TreeNode>(); int current = 0 , next = 1 ; levels[current].push(pRoot); ArrayList<Integer> layer = new ArrayList <>(); while (!levels[0 ].isEmpty() || !levels[1 ].isEmpty()){ TreeNode pNode = (TreeNode) levels[current].pop(); layer.add(pNode.val); if (current == 0 ){ if (pNode.left != null ) levels[next].push(pNode.left); if (pNode.right != null ) levels[next].push(pNode.right); }else { if (pNode.right != null ) levels[next].push(pNode.right); if (pNode.left != null ) levels[next].push(pNode.left); } if (levels[current].isEmpty()){ layerList.add(layer); layer = new ArrayList <>(); current = 1 - current; next = 1 - next; } } return layerList; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 import java.util.ArrayList;import java.util.Arrays;import java.util.LinkedList;public class ZPrintTree { public ArrayList<ArrayList<Integer>> print (TreeNode pRoot) { ArrayList<ArrayList<Integer>> layerList = new ArrayList <>(); if (pRoot == null ) return layerList; LinkedList<TreeNode> stack1 = new LinkedList <>(); LinkedList<TreeNode> stack2 = new LinkedList <>(); stack1.push(pRoot); ArrayList<Integer> layer = new ArrayList <>(); while (!stack1.isEmpty() || !stack2.isEmpty()){ int size = stack1.size(); while (!stack1.isEmpty()){ TreeNode pNode = stack1.pop(); layer.add(pNode.val); if (pNode.left != null ) stack2.push(pNode.left); if (pNode.right != null ) stack2.push(pNode.right); } if (stack1.size() != size){ layerList.add(layer); layer = new ArrayList <>(); } size = stack2.size(); while (!stack2.isEmpty()){ TreeNode pNode = stack2.pop(); layer.add(pNode.val); if (pNode.right != null ) stack1.push(pNode.right); if (pNode.left != null ) stack1.push(pNode.left); } if (stack2.size() != size){ layerList.add(layer); layer = new ArrayList <>(); } } return layerList; } }
二叉搜索树的后序遍历序列
思路:
在后序遍历得到的序列中,最后一个数字是树的根结点的值。数组中前面的数字可以分为两部分:第一部分是左子树结点的值,它们都比根结点的值小;第二部分是右子树结点的值,它们都比根结点的值大。
以数组 {5,7,6,9,11,10,8} 为例,后序遍历结果的最后一个数字 8 就是根结点的值。在这个数组中,前 3 个数字 5、7 和 6 都比 8 小,是值为 8 的结点的左子树结点;后 3 个数字 9、11 和 10 都比 8 大,是值为 8 的结点的右子树结点。所以我们可以用同样的方法确定与数组每一部分对应的子树的结构。
时间复杂度: \(O(n)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class VerifySequenceOfBST { private boolean verifyCore (int [] sequence, int left, int right) { if (left >= right) return true ; int root = sequence[right], sep = left; while (sep < right && sequence[sep] < root) sep++; for (int i = sep + 1 ; i < right; i++) if (sequence[i] < root) return false ; return verifyCore(sequence, left, sep - 1 ) && verifyCore(sequence, sep, right - 1 ); } public boolean verifySequenceOfBST (int [] sequence) { if (sequence == null || sequence.length == 0 ) return false ; return verifyCore(sequence, 0 , sequence.length - 1 ); } }
二叉树中和为某一值的路径
思路:
经分析,当用前序遍历的方式访问到某一结点时,我们把该结点添加到路径上,并累加该结点的值。
如果该结点为叶子结点,并且路径中结点值的和刚好等于输入的整数,则当前路径符合要求,我们把它打印出来。
如果当前结点不是叶子结点,则继续访问它的子结点。
当前结点访问结束后,递归函数自动回到它的父结点。因此在函数退出之前要在路径上删除当前结点并减去当前结点的值,以确保返回父结点时路径刚好是从根结点到父结点。
时间复杂度: \(O(nlogn)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import java.util.ArrayList;public class FindPath { private void findPathCore (TreeNode root, int target, int [] curSum, ArrayList<Integer> curPath, ArrayList<ArrayList<Integer>> paths) { curSum[0 ] += root.val; curPath.add(root.val); if (root.left == null && root.right == null && curSum[0 ] == target) paths.add(new ArrayList <>(curPath)); if (root.left != null ) findPathCore(root.left, target, curSum, curPath, paths); if (root.right != null ) findPathCore(root.right, target, curSum, curPath, paths); curPath.remove(curPath.size()-1 ); curSum[0 ] -= root.val; } public ArrayList<ArrayList<Integer>> findPath (TreeNode root, int target) { ArrayList<ArrayList<Integer>> paths = new ArrayList <>(); if (root == null ) return paths; int [] curSum = new int []{0 }; ArrayList<Integer> curPath = new ArrayList <>(); findPathCore(root, target, curSum, curPath, paths); return paths; } }
分解让复杂问题简单化
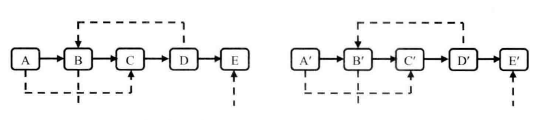
复杂链表的复制
思路:
第一步根据原始链表的每个结点 \(N\) 创建对应的 \(N'\) ,直接把 \(N'\) 链接在 \(N\) 的后面。经过这一步之后的结构如下:
第二步设置复制出来的结点的 random。假设原始链表上的 \(N\) 的 random 指向结点 \(S\) ,那么其对应复制出来的 \(N'\) 是 \(N\) 的 next 的指向的结点,同理 \(S'\) 也是 \(S\) 的 next 指向的结点。设置 random 之后的链表如图:
第三步把这个长链表拆分成两个链表:把奇数位置的结点用 next 连接起来就是原始链表,把偶数位置的结点用 next 链接起来就是复制出来的链表。链表拆分之后的两个链表如图:
时间复杂度: \(O(n)\)
额外空间复杂度为\(O(1)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 class RandomListNode { int label; RandomListNode next = null ; RandomListNode random = null ; RandomListNode(int label) { this .label = label; } } public class ComplexLinkedListCopy { private void cloneNodes (RandomListNode pHead) { RandomListNode pNode = pHead; while (pNode != null ){ RandomListNode pClone = new RandomListNode (pNode.label); pClone.next = pNode.next; pNode.next = pClone; pNode = pClone.next; } } private void connectRandomNodes (RandomListNode pHead) { RandomListNode pNode = pHead; while (pNode != null ){ RandomListNode pClone = pNode.next; if (pNode.random != null ) pClone.random = pNode.random.next; pNode = pClone.next; } } private RandomListNode reconnectNodes (RandomListNode pHead) { RandomListNode pNode = pHead; RandomListNode pCloneHead = null , pCloneNode = null ; if (pNode != null ){ pCloneHead = pCloneNode = pNode.next; pNode.next = pCloneNode.next; pNode = pNode.next; } while (pNode != null ){ pCloneNode.next = pNode.next; pCloneNode = pCloneNode.next; pNode.next = pCloneNode.next; pNode = pNode.next; } return pCloneHead; } public RandomListNode clone (RandomListNode pHead) { cloneNodes(pHead); connectRandomNodes(pHead); return reconnectNodes(pHead); } }
二叉搜索树与双向链表
思路:
在二叉搜索树中,左子结点的值总是小于父结点的值,右子结点的值总是大于父结点的值。因此我们在将二叉搜索树转换成排序双向链表时,原先指向左子结点的指针调整为链表中指向前一个结点的指针,原先指向右子结点的指针调整为链表中指向后一个结点的指针。
按照中序遍历的顺序,当我们遍历转换到根结点时,它的左子树已经转换成一个排序的链表了,并且处在链表中的最后一个结点是当前值最大的结点。我们把这个结点和根结点链接起来,此时链表中的最后一个结点就是根结点了。接着我们去遍历转换右子树,并把根结点和右子树中最小的结点链接起来。子树的转换过程是一样的,所以我们可以用递归解决。
时间复杂度: \(O(n)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public class BSTreeConvertToDLList { private void convertNode (TreeNode pRoot, TreeNode[] pLast) { if (pRoot == null ) return ; convertNode(pRoot.left, pLast); pRoot.left = pLast[0 ]; if (pLast[0 ] != null ) pLast[0 ].right = pRoot; pLast[0 ] = pRoot; convertNode(pRoot.right, pLast); } public TreeNode convert (TreeNode pRoot) { if (pRoot == null ) return null ; TreeNode[] pLast = new TreeNode []{null }; convertNode(pRoot, pLast); TreeNode pHeadOfList = pRoot; while (pHeadOfList.left != null ) pHeadOfList = pHeadOfList.left; return pHeadOfList; } }
序列化二叉树
思路:
序列化
根据前序遍历的顺序来序列化二叉树;
在遍历时,遇到 null 指针时,将这些 null 指针序列化为一个特殊的字符(如 $ );
其次结点的数值之间要用一个特殊的字符(如 , )隔开。
反序列化
以 "1,2,4,$,$,$,3,5,$,$,6,$,$" 为例:
第一个读出的是 1,由于前序遍历是从根结点开始的,这是根结点的值。
接下来读出的是 2,根据前序遍历的规则,这是根结点的左子结点。
同样,接下来的 4 是 2 的左子结点。
接着从序列读出两个 $,这表明 4 的左、右子结点均为 null,因此它是一个叶子结点。
接下来回到 2 的结点,重建它的右子结点。
由于下一个是 $,这表明 2 的右子结点为 null,说明这个结点的左、右子树都已构建完毕。
接下来回到根结点,同样的方法反序列化根结点的右子树。
时间复杂度: \(O(n)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 public class SerializeAndDeserialize { private StringBuilder sb = new StringBuilder (); private String[] nodes; private int index = -1 ; private void toSerial (TreeNode root) { if (root == null ){ sb.append("#," ); return ; } sb.append(root.val).append(',' ); toSerial(root.left); toSerial(root.right); } public String serialize (TreeNode root) { toSerial(root); return sb.toString(); } private TreeNode toDeserial () { if (!nodes[++index].equals("#" )){ TreeNode root = new TreeNode (Integer.valueOf(nodes[index])); root.left = toDeserial(); root.right = toDeserial(); return root; } return null ; } public TreeNode deserailize (String str) { if (str != null ) nodes = str.split("," ); return toDeserial(); } }
字符串的排列
思路:
把一个字符串看成由两部分组成:第一部分是它的第一个字符;第二部分是后面的所有字符。求整个字符串的排列,可以看成两步:
第一步求所有可能出现在第一个位置的字符,即把第一个字符和后面所有的字符交换。
第二步固定第一个字符,求后面所有字符的排列,这时仍把后面的所有字符分成两部分:后面字符的第一个字符,以及这个字符之后的所有字符。然后进行同样的操作。
时间复杂度: \(O(n)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import java.util.ArrayList;import java.util.Collections;public class Permutation { private void swap (char [] arr, int i, int j) { char tmp = arr[i]; arr[i] = arr[j]; arr[j] = tmp; } private void permutationCore (char [] arr, int start, ArrayList<String> res) { if (start == arr.length) res.add(new String (arr)); for (int i = start; i < arr.length; i++){ if (i != start && arr[i] == arr[start]) continue ; swap(arr, i, start); permutationCore(arr, start + 1 , res); swap(arr, i, start); } } public ArrayList<String> permutation (String str) { ArrayList<String> res = new ArrayList <>(); if (str == null || str.length() == 0 ) return res; permutationCore(str.toCharArray(), 0 , res); Collections.sort(res); return res; } }
优化时间和空间效率
时间效率
数组中出现次数超过一半的数字
思路:
数组中有一个数字出现的次数超过数组长度的一半,也就是说它出现的次数比其它所有数字出现次数的和还要多。因此我们可以考虑 在遍历数组的时候保存两个值:一个是数组中的一个数字,一个是次数。
当我们遍历到下一个数字的时候,如果下一个数字和我们之前保存的数字相同,则次数加 1;如果下一个数字和我们之前保存的数字不同,则次数减 1。如果次数为 0,则保存下一个数字,并把次数设为 1。
由于要找的数字出现的次数比其他所有数字出现的次数之和还要多,那么要找的数字肯定是最后一次吧次数设为 1 时对应的数字。
时间复杂度: \(O(n)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public class MoreThanHalfNum { private static boolean checkMoreThanHalf (int [] arr, int result) { int times = 0 ; for (int anArr : arr) if (anArr == result) times++; return times > arr.length / 2 ; } public static int moreThanHalfNum (int [] arr) { if (arr == null || arr.length == 0 ) return 0 ; int result = arr[0 ]; int times = 1 ; for (int i = 1 ; i < arr.length; i++){ if (arr[i] == result) times++; else if ((--times) == 0 ){ result = arr[i]; times = 1 ; } } return checkMoreThanHalf(arr, result) ? result : 0 ; } public static void main (String[] args) { int [] arr = new int []{1 ,2 ,3 ,2 ,2 ,2 ,5 ,4 ,2 }; System.out.println(moreThanHalfNum(arr)); } }
最小的 k 个数
思路:
可以基于 partition 函数来解决这个问题。
如果基于数组的第 k 个数字来调整,使得比第 k 个数字小的所有数字都位于数组的左边,比第 k 个数字大的所有数字都位于数组的右边。这样调整之后,位于数组中左边的 k 个数字就是最小的 k 个数字(这 k 个数字不一定是排序的)。
时间复杂度: \(O(n)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 import java.util.ArrayList;public class GetLeastNumbers { private static void swap (int [] arr, int i, int j) { int tmp = arr[i]; arr[i] = arr[j]; arr[j] = tmp; } private static int partition (int [] arr, int left, int right) { int j = left - 1 ; for (int i = left; i < right; i++) if (arr[i] <= arr[right]) swap(arr, i, ++j); swap(arr, ++j, right); return j; } private static int partition2 (int [] arr, int left, int right) { int i = left, j = right, base = arr[left], tmp; while (i < j){ while (arr[j] >= base && i < j) j--; while (arr[i] <= base && i < j) i++; if (i < j){ tmp = arr[i]; arr[i] = arr[j]; arr[j] = tmp; } } arr[left] = arr[i]; arr[i] = base; return i; } public static ArrayList<Integer> getLeastNumbers (int [] input, int k) { ArrayList<Integer> result = new ArrayList <>(); if (input == null || input.length == 0 || k <= 0 || k > input.length) return result; int left = 0 , right = input.length - 1 ; int index = partition(input, left, right); while (index != k - 1 ){ if (index > k -1 ) right = index - 1 ; else left = index + 1 ; index = partition(input, left, right); } for (int i = 0 ; i < k; i++) result.add(input[i]); return result; } public static void main (String[] args) { int [] arr = new int []{4 ,5 ,1 ,6 ,2 ,7 ,3 ,8 }; ArrayList<Integer> res = getLeastNumbers(arr, 4 ); for (int e: res) { System.out.print(e + " " ); } } }
数据流中的中位数
思路:
如果数据在容器中已经排序,那么中位数可以由 \(P_1\) 和 \(P_2\) 指向的数得到。如果容器中的数据的数目是奇数,那么 \(P_1\) 和 \(P_2\) 指向同一个数据。
\(P_1\) 指向的数据是左边部分的最大的数,\(P_2\) 指向的数据是左边部分最小的数。如果能够保证容器左边的数据小于右边的数据,那么即使左右两边内部的数据没有排序,也可以根据左边最大的数及右边最小的数得到中位数。
可以用一个最大堆实现左边的数据容器,用一个最小堆实现右边的数据容器。往堆中插入一个数据的时间效率是 \(O(logn)\) ;得到中位数的时间复杂度是 \(O(1)\) 。
插入时要保证数据平均分配到两个堆中,因此两个堆中数据的数目之差不能超过1。
可以在数据的总数目是偶数时把新数据插入最小堆,否则插入最大堆。
在插入时同时要保证最大堆的所有数据都要小于最小堆的数据。
时间复杂度: 插入一个数据的时间效率是 \(O(logn)\) ;得到中位数的时间复杂度是 \(O(1)\) 。
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import java.util.PriorityQueue;public class MedianOfDataStream { private int count = 0 ; private PriorityQueue<Integer> minHeap = new PriorityQueue <>(); private PriorityQueue<Integer> maxHeap = new PriorityQueue <>(16 , (o1, o2) -> o2 - o1); public void insert (Integer num) { if (count % 2 == 0 ){ maxHeap.offer(num); minHeap.offer(maxHeap.poll()); }else { minHeap.offer(num); maxHeap.offer(minHeap.poll()); } count++; } public Double getMedian () { return (count % 2 == 0 ) ? (maxHeap.peek() + minHeap.peek()) / 2.0 : 1.0 * minHeap.peek(); } }
连续子数组的最大和
思路:
可以利用动态规划来解决这个问题。
如果用函数 dp[i] 表示以第 i 个数字结尾的子数组的最大和,那么我们要求出 max(dp[i]),其中 0<=i<=n。状态转移方程如下:
\[
dp[i] = \left\{\begin{aligned}
& arr[i] & & {i=0\ or\ dp[i-1] \le 0 }\\
& dp[i-1]+arr[i] & & {i \neq 0\ and\ dp[i-1] \gt 0}
\end{aligned}\right.
\]
这个公式的意义:当以第 i-1 个数字结尾的子数组的最大和小于等于 0 时,如果把这个负数与第 i 个数累加,得到的结果比第 i 个数字本身还要小,所以这种情况下以第 i 个数字结尾的子数组的最大和就是第 i 个数字本身。
如果以第 i-1 个数字结尾的子数组的最大和大于 0,则与第 i 个数字累加就得到以第 i 个数字为结尾的子数组的最大和。
时间复杂度: \(O(n)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class FindGreatestSumOfSubArray { public static int findGreatestSumOfSubArray (int [] arr) { int curSum = arr[0 ]; int maxSum = curSum; for (int i = 1 ; i < arr.length; i++){ if (curSum <= 0 ) curSum = arr[i]; else curSum += arr[i]; if (curSum > maxSum) maxSum = curSum; } return maxSum; } public static void main (String[] args) { int [] arr = new int []{1 , -2 , 3 , 10 , -4 , 7 , 2 , -5 }; System.out.println(findGreatestSumOfSubArray(arr)); } }
从 1 到 n 整数中 1 出现的次数
思路:
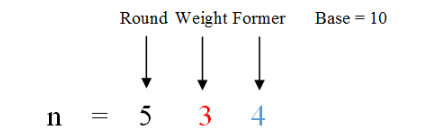
https://blog.csdn.net/yi_Afly/article/details/52012593
对每一位来说,记每一位的权值为 base,位值为 weight,该位之前的数是 former,举例如下:
则有:
若 weight = 0,则 1 出现的次数为 round * base
若 weight = 1,则 1 出现的次数为 round * base + former + 1
若 weight > 1,则 1 出现的次数为 round * base + base
注:\(base=10^i\) ,i 为当前位右边位的个数,如当前位为个位,则 i=0
时间复杂度: \(O(logn)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class NumberOf1Between1AndN { public static int countNumberOfOne (int n) { if (n < 1 ) return 0 ; int counter = 0 , base = 1 , round = n; while (round > 0 ){ int weight = round % 10 ; round /= 10 ; counter += round * base; if (weight == 1 ) counter += (n % base + 1 ); else if (weight > 1 ) counter += base; base *= 10 ; } return counter; } public static void main (String[] args) { System.out.println(countNumberOfOne(534 )); } }
把数组排成最小的数
思路:
对数组进行排序,排序时需要判断 a 和 b 哪个应该排在前面,判断规则如下:
将 a 和 b 分别拼接成 ab 和 ba,比较 ab 和 ba 的字典序:
若 ab < ba,则 a 应该排在 b 前面
若 ab = ba,说明 a=b
若 ab > ba,则 b 应该排在 a 前面
时间复杂度: \(O(nlogn)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 public class PrintMinNumber { private static void swap (int [] arr, int i, int j) { int tmp = arr[i]; arr[i] = arr[j]; arr[j] = tmp; } private static boolean compare (String a, String b) { String ab = a + b, ba = b + a; return ab.compareTo(ba) < 0 ; } private static int partition (int [] arr, int left, int right) { int j = left - 1 ; for (int i = left; i < right; i++) if (compare(String.valueOf(arr[i]), String.valueOf(arr[right]))) swap(arr, i, ++j); swap(arr, right, ++j); return j; } private static void quickSort (int [] arr, int left, int right) { if (left < right){ int index = partition(arr, left, right); quickSort(arr, left, index - 1 ); quickSort(arr, index + 1 , right); } } public static String printMinNumber (int [] arr) { quickSort(arr, 0 , arr.length - 1 ); StringBuilder sb = new StringBuilder (); for (int e: arr) sb.append(e); return sb.toString(); } public static void main (String[] args) { int [] arr = new int []{3 ,32 ,321 }; System.out.println(printMinNumber(arr)); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import java.util.ArrayList;public class PrintMinNumber { public static String printMinNumber (int [] arr) { ArrayList<Integer> arrayList = new ArrayList <>(); for (int anArr : arr) arrayList.add(anArr); arrayList.sort((o1, o2) -> { String ab = o1.toString() + o2.toString(); String ba = o2.toString() + o1.toString(); return ab.compareTo(ba); }); StringBuilder sb = new StringBuilder (); for (int e: arrayList) sb.append(e); return sb.toString(); } public static void main (String[] args) { int [] arr = new int []{3 ,32 ,321 }; System.out.println(printMinNumber(arr)); } }
时间效率与空间效率的平衡
丑数
思路:
用空间换时间,创建一个数组,保存排好序的丑数,利用已得到的丑数计算出下一个丑数,并将新的丑数加到数组尾部。
利用已得有序丑数计算下一个丑数的思路:
每一个丑数都是前面的丑数乘以 2、3 或者 5 得到的(除 1 以外)。
假设已有最大的丑数记为 \(M\)
\(T_2\) 代表着数组的某个丑数的下标,这个丑数满足 \(arr[T_2] \ast 2 > M\) ,同时若有任意小于 \(arr[T_2]\) 的丑数 \(arr[T]\) ,则 \(T\) 满足 \(arr[T] \ast 2 \le M\) ,\(T_3\) 、\(T_5\) 的含义与 \(T_2\) 类似\(M_2 = arr[T_2] \ast 2\) ,\(M_3 = arr[T_3] \ast 3\) ,\(M_5 = arr[T_5] \ast 5\) ,则下一个丑数为 \(M' = min(M_2, M_3, M_5)\) 每次计算完下一个丑数 \(M'\) ,及时更新 \(T_2\) 、\(T_3\) 、\(T_5\)
时间复杂度: \(O(n)\)
额外空间复杂度为 \(O(n)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public class GetUglyNumber { public static int getUglyNumber (int n) { if (n < 1 ) return 0 ; int [] arr = new int [n]; arr[0 ] = 1 ; int t2 = 0 , t3 = 0 , t5 = 0 ; for (int i = 1 ; i < n; i++){ int m2 = arr[t2] * 2 , m3 = arr[t3] * 3 , m5 = arr[t5] * 5 ; arr[i] = Math.min(Math.min(m2, m3), m5); while (arr[t2] * 2 <= arr[i]) t2++; while (arr[t3] * 3 <= arr[i]) t3++; while (arr[t5] * 5 <= arr[i]) t5++; } return arr[n-1 ]; } public static void main (String[] args) { System.out.println(getUglyNumber(3 )); } }
第一个只出现一次的字符
思路:
用空间换时间,创建一个数组,保存每个字母出现的次数,该数组相当于一个哈希表。
为了解决这个问题,需要从头开始扫描字符串两次:
第一次扫描时,每扫描到一个字符就在数组的对应项中把次数加1
第二次扫描时,每扫描到一个字符就从数组中取出对应出现的次数
这样第一个只出现一次的字符就是符合要求的输出。
时间复杂度: \(O(n)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class FirstNotRepeatingChar { public static int firstNotRepeatingChar (String str) { int [] counters = new int [123 ]; for (int i = 0 ; i < str.length(); i++) counters[str.charAt(i)]++; for (int i = 0 ; i < str.length(); i++) if (counters[str.charAt(i)] == 1 ) return i; return -1 ; } public static void main (String[] args) { System.out.println(firstNotRepeatingChar("abaccdeff" )); } }
字符流中第一个只出现一次的字符
思路:
用空间换时间,创建一个数组,保存 字符在字符流中的位置 。
当一个字符第一次从字符流中读出来时,把它在字符流中的位置保存到数据容器中。
当这个字符再次从字符流中读出来时,那么它就不是只出现一次的字符,也就可以被忽略了。这时把它在数据容器中保存的值更新成一个特殊的值。
时间复杂度: \(O(1)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 public class CharStatistics { private int index; private int [] occurrence = new int [256 ]; { for (int i = 0 ; i < 256 ; i++) occurrence[i] = -1 ; } public void insert (char ch) { if (occurrence[ch] == -1 ) occurrence[ch] = index; else if (occurrence[ch] >= 0 ) occurrence[ch] = -2 ; index++; } public char firstAppearingOnce () { char ch = '#' ; int minIdx = Integer.MAX_VALUE; for (int i = 0 ; i < 256 ; i++){ if (occurrence[i] >= 0 && occurrence[i] < minIdx){ ch = (char ) i; minIdx = occurrence[i]; } } return ch; } public static void main (String[] args) { CharStatistics statistics = new CharStatistics (); for (char ch : "google" .toCharArray()) { statistics.insert(ch); System.out.println(statistics.firstAppearingOnce()); } } }
数组中的逆序对
思路:
利用归并排序统计逆序对数。
把数组分隔成子数组
先统计出子数组内部的逆序对的数目
然后再统计出两个相邻子数组之间的逆序对的数目
在统计逆序对的过程中,还需要对数组进行排序。
时间复杂度: \(O(nlogn)\)
额外空间复杂度 \(O(n)\)
参考实现:
可能会溢出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 public class InversePairsCore { private static int merge (int [] arr, int left, int mid, int right, int [] tmp) { int i = mid, j = right, k = right, counter = 0 ; while (i >= left && j >= mid + 1 ){ if (arr[i] > arr[j]){ counter += (j - mid); tmp[k--] = arr[i--]; }else { tmp[k--] = arr[j--]; } } while (i >= left) tmp[k--] = arr[i--]; while (j >= mid + 1 ) tmp[k--] = arr[j--]; k = left; while (left <= right) arr[left++] = tmp[k++]; return counter; } private static int mergeSort (int [] arr, int left, int right, int [] tmp) { if (left < right){ int mid = (left + right) / 2 ; int part1 = mergeSort(arr, left, mid, tmp); int part2 = mergeSort(arr, mid + 1 , right, tmp); int part3 = merge(arr, left, mid, right, tmp); return part1 + part2 + part3; } return 0 ; } public static int inversePairs (int [] arr) { return mergeSort(arr, 0 , arr.length - 1 , new int [arr.length]); } public static void main (String[] args) { int [] arr = new int []{1 ,2 ,3 ,4 ,5 ,6 ,7 ,0 }; System.out.println(inversePairs(arr)); } }
两个链表的第一个公共结点
思路:
从结点的定义看,两个链表为单链表,如果两个链表有公共结点,那么从第一公共结点开始,之后它们的所有结点都是重合的,不可能在出现分叉。所以两个有公共结点而部分重合的链表,其拓扑形状看起来像一个 Y,而不可能像 X。
这道题的关键是当两个链表的长度不相同时,如何同时遍历到两个链表的第一个公共结点,利用两个辅助栈可以实现从链表尾部开始同时遍历到第一个公共结点,但是我们有更简单的方法:
首先遍历两个链表得到它们的长度
在第二次遍历的时候,在较长的链表上先走若干步,使得剩余步数与另一链表一致
接着同时在两个链表遍历,找到的第一个相同的结点即为它们的第一个公共结点
时间复杂度: \(O(m+n)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 class ListNode { int val; ListNode next = null ; ListNode(int val) { this .val = val; } } public class FindFirstCommonNode { private static int getListLength (ListNode pHead) { int len = 0 ; ListNode pNode = pHead; while (pNode != null ){ len++; pNode = pNode.next; } return len; } public static ListNode findFirstCommonNode (ListNode pHead1, ListNode pHead2) { if (pHead1 == null || pHead2 == null ) return null ; int len1 = getListLength(pHead1); int len2 = getListLength(pHead2); ListNode pNode1 = pHead1, pNode2 = pHead2; int t = Math.abs(len1 - len2); if (len1 < len2){ while (t-- != 0 ) pNode2 = pNode2.next; }else if (len1 > len2){ while (t-- != 0 ) pNode1 = pNode1.next; } while (pNode1 != pNode2){ pNode1 = pNode1.next; pNode2 = pNode2.next; } return pNode1; } public static void main (String[] args) { ListNode node7 = new ListNode (7 ); ListNode node6 = new ListNode (6 ); node6.next = node7; ListNode node3 = new ListNode (3 ); ListNode node5 = new ListNode (5 ); node3.next = node6; node5.next = node6; ListNode node4 = new ListNode (4 ); node4.next = node5; ListNode node2 = new ListNode (2 ); node2.next = node3; ListNode node1 = new ListNode (1 ); node1.next = node2; System.out.println(findFirstCommonNode(node1, node4).val); } }
面试中的各项能力
知识迁移能力
数字在排序数组中出现的次数
思路:
因为数组是有序的,要快速统计数字 k 出现的次数的关键是如何找到第一个 k 和最后一个 k,最后一个k的索引 - 第一个k的索引 + 1 即为 k 出现的次数。而第一个 k 和最后一个 k 的查找可以使用二分查找得到。
时间复杂度: \(O(logn)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 public class GetNumberOfK { private static int getFirstK (int [] arr, int left, int right, int k) { while (left <= right){ int mid = (left + right) / 2 ; if (arr[mid] == k){ if (mid == left || arr[mid-1 ] != k) return mid; right = mid - 1 ; }else if (arr[mid] < k) left = mid + 1 ; else right = mid - 1 ; } return -1 ; } private static int getLastK (int [] arr, int left, int right, int k) { while (left <= right){ int mid = (left + right) / 2 ; if (arr[mid] == k){ if (mid == right || arr[mid+1 ] != k) return mid; left = mid + 1 ; }else if (arr[mid] < k) left = mid + 1 ; else right = mid - 1 ; } return -1 ; } public static int getNumberOfK (int [] arr, int k) { if (arr == null ) return -1 ; int firstK = getFirstK(arr, 0 , arr.length - 1 , k); int lastK = getLastK(arr, 0 , arr.length - 1 , k); if (firstK == -1 ) return 0 ; return lastK - firstK + 1 ; } public static void main (String[] args) { int [] arr = new int []{1 ,2 ,3 ,3 ,3 ,3 ,4 ,5 }; System.out.println(getNumberOfK(arr, 3 )); } }
二叉搜索树的第 k 大结点
思路:
如果按照中序遍历的顺序遍历一棵二叉搜索树,则遍历序列的数值是递增排序的。
时间复杂度: \(O(n)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class KthNode { private void kthNode (TreeNode pRoot, ArrayList<TreeNode> nodes) { if (pRoot.left != null ) kthNode(pRoot.left, nodes); nodes.add(pRoot); if (pRoot.right != null ) kthNode(pRoot.right, nodes); } public TreeNode kthNode (TreeNode pRoot, int k) { if (pRoot == null || k < 1 ) return null ; ArrayList<TreeNode> nodes = new ArrayList <>(); kthNode(pRoot, nodes); return k > nodes.size() ? null : nodes.get(k-1 ); } }
二叉树的深度
思路:
可以从另一个角度来理解树的深度。如果一棵树只有一个结点,它的深度为 1。如果根结点只有左子树而没有右子树,那么树的深度应该是其左子树的深度加 1;同样如果根结点只有右子树而没有左子树,那么树的深度就是其左、右子树深度的较大值再加 1。
时间复杂度: \(O(logn) \sim O(n)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 class TreeNode { int val; TreeNode left = null ; TreeNode right = null ; public TreeNode (int val) { this .val = val; } } public class TreeDepth { public static int treeDepth (TreeNode root) { if (root == null ) return 0 ; return Math.max(treeDepth(root.left) + 1 , treeDepth(root.right) + 1 ); } public static void main (String[] args) { TreeNode node7 = new TreeNode (7 ); TreeNode node5 = new TreeNode (5 ); node5.left = node7; TreeNode node4 = new TreeNode (4 ); TreeNode node2 = new TreeNode (2 ); node2.left = node4; node2.right = node5; TreeNode node6 = new TreeNode (6 ); TreeNode node3 = new TreeNode (3 ); node3.right = node6; TreeNode node1 = new TreeNode (1 ); node1.left = node2; node1.right = node3; System.out.println(treeDepth(node1)); } }
判断平衡二叉树
思路:
如果某二叉树中任意结点的左右子树的深度相差不超过 1,那么它就是一颗平衡二叉树。
利用后序遍历的方式遍历二叉树的每一个结点,在遍历到一个结点之前我们就已经遍历了它的左右子树。只要在遍历每个结点的时候记录它的深度,我们就可以一边遍历一边判断每个结点是不是平衡的。
时间复杂度: \(O(logn)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public class IsAVLTree { private static int getDepth (TreeNode root) { if (root == null ) return 0 ; int left = getDepth(root.left); if (left == -1 ) return -1 ; int right = getDepth(root.right); if (right == -1 ) return -1 ; return Math.abs(left - right) > 1 ? -1 : Math.max(left, right) + 1 ; } public static boolean isBalanced (TreeNode root) { return getDepth(root) != -1 ; } public static void main (String[] args) { TreeNode node3 = new TreeNode (3 ); TreeNode node2 = new TreeNode (2 ); TreeNode node1 = new TreeNode (1 ); node1.left = node2; node1.right = node3; System.out.println(isBalanced(node1)); } }
数组中只出现一次的数字
要求时间复杂度是 \(O(n)\) ,空间复杂度为 \(O(1)\)
思路:
异或运算的一个性质:任何一个数字异或它自己都等于 0
如果数组里只有一个数字出现 1 次,其它都出现偶数次,那么从头到尾异或数组中的每一个数字,最后将得到那个只出现一次的数字。所以解决问题的关键变成了如何把原数组分成两个子数组,使得每个子数组包含一个只出现一次的数字,而其它数字都出现偶数次。
并不需要额外的辅助空间保存两个子数组,这里只是在逻辑上进行划分而已。
首先,从头到尾依次异或数组中的每一个数字,最终得到的结果就是那两个只出现一次的数字异或的结果。
因为这两个数字肯定不一样,那么异或的结果肯定不为 0,也就是说在这个结果数字的二进制表示中至少有一位为 1。
在结果数字中找到第一个为 1 的位置,记为第 n 位。
接着,以第 n 位是不是 1 为标准把原数组中的数字分成两个子数组,第一个子数组中每个数字的第 n 位都是 1,第二个子数组中每一个数字的第 n 位都是 0。
由于分组的标准是数字中的某一位是 1 还是 0,那么出现了偶数次的数字肯定被分配到同一个子数组。因为两个相同的数字的任意一位都是相同的。
例如:
假设输入数组 {2,4,3,6,3,2,5,5},对数组中的每个数字异或运算后得到结果的二进制表示为 0010。
异或得到结果中的倒数第二位是 1,于是我们根据数字的倒数第二位是不是 1 分为两个子数组。
第一个子数组 {2,3,6,3,2} 中所有数字的倒数第二位都是 1;而第二个子数组 {4,5,5} 中所有数字的倒数第二位都是 0。
时间复杂度: \(O(n)\)
额外空间复杂度为\(O(1)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public class FindNumsAppearOnce { private static int findFirstBitIsOne (int num) { int counter = 0 ; while ((num >>>= 1 ) != 0 ) counter++; return counter; } private static boolean isBitOne (int num, int indexBit) { return (num >>> indexBit & 1 ) == 1 ; } public static void findNumsAppearOnce (int [] arr, int [] num1, int [] num2) { if (arr == null || arr.length < 2 ) return ; int resExclusiveOr = 0 ; for (int e : arr) resExclusiveOr ^= e; int indexBit = findFirstBitIsOne(resExclusiveOr); num1[0 ] = 0 ; num2[0 ] = 0 ; for (int e : arr) { if (isBitOne(e, indexBit)) num1[0 ] ^= e; else num2[0 ] ^= e; } } public static void main (String[] args) { int [] arr = new int []{2 ,4 ,3 ,6 ,3 ,2 ,5 ,5 }; int [] num1 = new int [1 ], num2 = new int [1 ]; findNumsAppearOnce(arr, num1, num2); System.out.println("num1=" + num1[0 ] + " num2=" + num2[0 ]); } }
和为S的两个数字
思路:
因为数组有序,所以如果找到的两个数字小于 S,则考虑选择较小数字后面的数字,因为排在后面的数字更大一些,那么两个数字的和也更大一些,就有可能等于 S 了;同样,当两个数字的和大于 S,可以选择较大数字前面的数字,因为排在数组前面的数字要小一些。
以数组 {1,2,4,7,11,15} 及 S=15 为例:
首先定义两个指针,第一个指向数组的第一个(也是最小的)数字 1;第二个指向数组的最后一个(也是最大的)数字 15。
这两个数字的和 16 大于 15,因此把第二个指针向前移动一个数字,让它指向 11。
这时两个数字 1 与 11 的和是 12,小于 15,所以把第一个指针向后移动一个数字指向 2。
此时两个数字 2 与 11 的和是 13,还是小于 15,所以再次把第一个指针向后移动一个数字指向 4。
此时数字 4 与 11 的和是 15,正是我们期待的结果。
时间复杂度: \(O(n)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import java.util.ArrayList;import java.util.Arrays;public class FindNumbersWithSum { private static boolean findNumbers (int [] arr, int [] num1, int [] num2, int sum) { if (arr == null || arr.length < 1 || num1 == null || num2 == null ) return false ; int left = 0 , right = arr.length - 1 ; while (left < right) { long curSum = arr[left] + arr[right]; if (curSum == sum) { num1[0 ] = arr[left]; num2[0 ] = arr[right]; return true ; } else if (curSum > sum) right--; else left++; } return false ; } public static ArrayList<Integer> findNumbersWithSum (int [] arr, int sum) { ArrayList<Integer> numsList = new ArrayList <>(2 ); int [] num1 = new int [1 ], num2 = new int [1 ]; if (findNumbers(arr, num1, num2, sum)) { numsList.add(num1[0 ]); numsList.add(num2[0 ]); } return numsList; } public static void main (String[] args) { int [] arr = new int []{1 , 2 , 4 , 7 , 11 , 15 }; System.out.println(Arrays.toString(findNumbersWithSum(arr, 15 ).toArray())); } }
和为S的连续正数序列
思路:
考虑用两个数 small 和 big 分别表示序列的最小值和最大值。
首先把 small 初始化为 1,big 初始化为 2
如果从 small 到 big 的序列的和大于 S,我们可以从序列中去掉较小的值,也就是增大 small 的值
如果从 small 到 big 的序列的和小于 S,我们可以增大 big,让这个序列包含更多的数字
因为这个序列至少要有两个数字,所以 small 需要一直增加到 S/2 为止
以 S=9 为例,求取和为 9 的连续序列的过程:
1
1
2
1,2
3
小于
增加 big
2
1
3
1,2,3
6
小于
增加 big
3
1
4
1,2,3,4
10
大于
增加 small
4
2
4
2,3,4
9
等于
保存序列,增加 big
5
2
5
2,3,4,5
14
大于
增加 small
6
3
5
3,4,5
12
大于
增加 small
7
4
5
4,5
9
等于
保存序列
时间复杂度: \(O(n)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import java.util.ArrayList;import java.util.Arrays;public class FindContinuousSequence { private static ArrayList<Integer> getSequence (int small, int big) { ArrayList<Integer> sequence = new ArrayList <>(); for (int i = small; i <= big; i++) sequence.add(i); return sequence; } public static ArrayList<ArrayList<Integer>> findContinuousSequence (int sum) { ArrayList<ArrayList<Integer>> sequencesList = new ArrayList <>(); if (sum < 3 ) return sequencesList; int small = 1 , big = 2 , mid = sum / 2 ; int curSum = small + big; while (small <= mid){ if (curSum == sum){ sequencesList.add(getSequence(small, big)); curSum += (++big); } else if (curSum > sum) curSum -= (small++); else curSum += (++big); } return sequencesList; } public static void main (String[] args) { ArrayList<ArrayList<Integer>> sequencesList = findContinuousSequence(9 ); for (ArrayList<Integer> e: sequencesList) { System.out.println(Arrays.toString(e.toArray())); } } }
翻转单词顺序
思路:
第一步翻转句子中所有的字符。比如翻转 "I am a student." 中所有的字符得到 ".tneduts a ma I",此时不但翻转了句子中单词的顺序,连单词内的字符顺序也被翻转了。
第二步再翻转每个单词中字符的顺序,就得到了 "student. a am I"。
这种思路的关键在于实现一个函数以翻转字符串中的一段。
时间复杂度: \(O(n)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public class ReverseSentence { private static void reverse (char [] arr, int left, int right) { while (left < right){ char tmp = arr[left]; arr[left++] = arr[right]; arr[right--] = tmp; } } public static String reverseSentence (String str) { if (str == null ) return null ; char [] arr = str.toCharArray(); reverse(arr, 0 , arr.length - 1 ); int left = 0 ; for (int i = 0 ; i < arr.length - 1 ; i++){ if (arr[i] == ' ' ){ reverse(arr, left, i - 1 ); left = i + 1 ; } } reverse(arr, left, arr.length - 1 ); return new String (arr); } public static void main (String[] args) { System.out.println(reverseSentence("I am a student." )); System.out.println(reverseSentence("Wonderful" )); } }
左旋转字符串
思路:
利用三次逆序操作可以实现循环左移:
将字符串分成两部分,一部分是需要循环左移(也即移到字符串尾部)的序列,另一部分是剩余的序列
对这两部分序列分别进行逆序操作
对整个字符串进行逆序操作,即得到循环左移的结果
时间复杂度: \(O(n)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public class LeftRotateString { private static void reverse (char [] arr, int left, int right) { while (left < right){ char tmp = arr[left]; arr[left++] = arr[right]; arr[right--] = tmp; } } public static String leftRotateString (String str, int n) { if (str == null || n < 0 || n > str.length()) return "" ; char [] arr = str.toCharArray(); reverse(arr, 0 , n - 1 ); reverse(arr, n, arr.length - 1 ); reverse(arr, 0 , arr.length - 1 ); return new String (arr); } public static void main (String[] args) { System.out.println(leftRotateString("ABCDE" , 0 )); System.out.println(leftRotateString("ABCDE" , 3 )); System.out.println(leftRotateString("ABCDE" , 5 )); } }
6.1.10 队列的最大值
滑动窗口的最大值
思路:
使用一个双端队列,用来保存有可能是滑动窗口最大值的数字的下标。
在存入一个数字的下标之前,首先判断队列里已有数字是否小于待存入的数字。
如果已有的数字小于待存入的数字,那么这些数字已经不可能是滑动窗口的最大值,因此它们将会被依次从队列尾部删除。
同时,如果队列头部的数字已经从窗口里滑出,那么滑出的数字也需要从队列的头部删除。
时间复杂度: \(O(n)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import java.util.ArrayList;import java.util.LinkedList;public class MaxInWindows { public ArrayList<Integer> maxInWindows (int [] num, int size) { ArrayList<Integer> res = new ArrayList <>(); if (num == null || size < 1 || size > num.length) return res; LinkedList<Integer> deque = new LinkedList <>(); for (int i = 0 ; i < size; i++){ while (!deque.isEmpty() && num[i] >= num[deque.peekLast()]) deque.pollLast(); deque.offer(i); } for (int i = size; i < num.length; i++){ res.add(num[deque.peek()]); while (!deque.isEmpty() && num[i] >= num[deque.peekLast()]) deque.pollLast(); if (!deque.isEmpty() && deque.peek() <= (i - size)) deque.poll(); deque.offer(i); } res.add(num[deque.peek()]); return res; } }
抽象建模能力
n 个骰子的点数
思路:
考虑用两个数组来存储骰子点数的每一个总数出现的次数。
在一次循环中,第一个数组中的第n个数字表示骰子和为n出现的次数。
在下一循环中,我们加上一个新的骰子,此时和为n的骰子出现的次数等于上一次循环中骰子点数和为 n-1、n-2、n-3、n-4、n-5 与 n-6 的次数的总和
所以我们把另一个数组的第 n 个数字设为前一个数组对应的第 n-1、n-2、n-3、n-4、n-5 与 n-6 个数之和
时间复杂度: \(O(n^2)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 public class PointsOfNDice { private void printProbability (int num) { if (num < 1 ) return ; int diceMaxVal = 6 ; int [][] count = new int [2 ][diceMaxVal * num + 1 ]; int flag = 0 ; for (int i = 1 ; i <= diceMaxVal; i++) count[flag][i] = 1 ; for (int k = 2 ; k <= num; k++) { for (int i = 0 ; i < k; i++) count[1 - flag][i] = 0 ; for (int i = k; i <= diceMaxVal * k; i++) { count[1 - flag][i] = 0 ; for (int j = 1 ; j < i && j <= diceMaxVal; j++) { count[1 - flag][i] += count[flag][i - j]; } } flag = 1 - flag; } double total = Math.pow(diceMaxVal, num); for (int i = num; i <= diceMaxVal * num; i++) { System.out.println(String.format("%d : %.6f" , i, count[flag][i] / total)); } } public static void main (String[] args) { new PointsOfNDice ().printProbability(3 ); } }
扑克牌的顺子
思路:
建模:把 5 张牌看成由 5 个数字组成的数组。大、小王定义为 0;A 为 1,J 为 11,Q 为 12,K 为 13。
首先把数组排序
然后统计数组中 0 的个数
最后统计排序后的数组中相邻数字之间的空缺总数
如果空缺总数小于或者等于 0 的个数,那么这个数组就是连续的;反之则不连续。
注意:如果数组中的非 0 数字重复出现,则该数组不是连续的。也即如果一副牌里含有对子,则不可能是顺子。
时间复杂度: \(O(nlogn)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public class IsContinuous { public static boolean isContinuous (int [] arr) { if (arr == null || arr.length != 5 ) return false ; Arrays.sort(arr); int numOfZero = 0 , numOfGap = 0 ; for (int i = 0 ; i < arr.length && arr[i] == 0 ; i++) numOfZero++; int small = numOfZero, big = numOfZero + 1 ; while (big < arr.length){ if (arr[small] == arr[big]) return false ; numOfGap += arr[big] - arr[small] - 1 ; small = big++; } return numOfZero >= numOfGap; } public static void main (String[] args) { int [] arr = new int []{1 ,2 ,0 ,0 ,3 }; System.out.println(isContinuous(arr)); } }
圆圈中最后剩下的数字
思路:
利用递推公式(推导过程详见《剑指Offer》)
\[
f(n,m) = \left\{\begin{aligned}
& 0 & & {n=1}\\
& (f(n-1,m)+m)\%n & & {n \gt 1}
\end{aligned}\right.
\]
时间复杂度: \(O(n)\)
额外空间复杂度为 \(O(1)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 public class LastRemaining { public static int lastRemaining (int n, int m) { if (n < 1 || m < 1 ) return -1 ; int last = 0 ; for (int i = 2 ; i <= n; i++) last = (last + m) % i; return last; } public static void main (String[] args) { System.out.println(lastRemaining(5 , 3 )); } }
发散思维能力
求 1+2+...+n
思路:
利用短路与的特性实现递归终止
时间复杂度: \(O(n)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 public class OneToNSum { public static int sumSolution (int n) { int sum = n; boolean ans = (n > 0 ) && ((sum += sumSolution(n-1 )) > 0 ); return sum; } public static void main (String[] args) { System.out.println(sumSolution(100 )); } }
不用加减乘除做加法
思路:
分析 5+17=22,实际上可以分成三步进行:
第一步只做各位相加不进位,此时相加结果是 12(个位 5 和 7 相加不进位是 2,十位 0 和 1 相加不进位是 1 )
第二步做进位,5+7 中有进位,进位值是 10
第三步把前面两个结果加起来,12+10=22,刚好为 5+17 的结果
这样的策略同样适用于二进制,所以可以了利用二进制的移位实现加法,具体的做法就是对二进制数进行以上三步操作,直至不产生进位(也即进位值等于 0 ),此时第一步的结果就是最终的结果。
时间复杂度: \(O(1)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class Add { public static int add (int num1, int num2) { int sum, carry; do { sum = num1 ^ num2; carry = (num1 & num2) << 1 ; num1 = sum; num2 = carry; }while (num2 != 0 ); return num1; } public static void main (String[] args) { System.out.println(add(3 , 8 )); } }
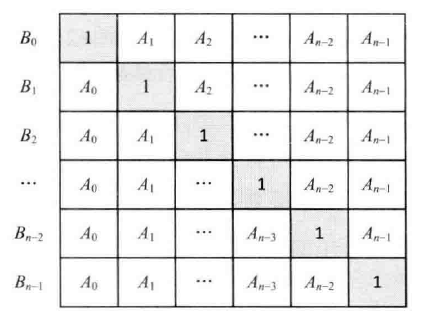
构建乘积数组
思路:
B[i] 的值可以看作如下矩阵中每行的乘积。先算下三角乘积,再算上三角乘积。
时间复杂度: \(O(n)\)
额外空间复杂度为 \(O(1)\)
参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import java.util.Arrays;public class CreateProductArray { public static int [] multiply(int [] arr) { if (arr == null || arr.length == 0 ) return null ; int [] res = new int [arr.length]; res[0 ] = 1 ; for (int i = 1 ; i < arr.length; i++) { res[i] = res[i - 1 ] * arr[i - 1 ]; } int tmp = 1 ; for (int i = arr.length - 2 ; i >= 0 ; i--){ tmp *= arr[i+1 ]; res[i] *= tmp; } return res; } public static void main (String[] args) { int [] arr = new int []{1 , 2 , 3 , 4 , 5 }; System.out.println(Arrays.toString(multiply(arr))); } }